I am a Ph.D. student in Computer Science at Stanford University, advised by Prof. Chelsea Finn and Prof. Dorsa Sadigh. Previously, I obtained my bachelor's degree from the Institute for Interdisciplinary Information Sciences (Yao Class) at Tsinghua University, advised by Prof. Yi Wu. I was honored to receive Yao Award (Gold Medal), the highest honor of our department. I was very fortunate to work with Prof. Yuke Zhu as a visiting researcher in UT Austin.
I am broadly interested in machine learning and robotics. My research goal is to develop efficient learning methods to build autonomous robots with robust and generalizable behaviors that help humans do a wide range of real-world tasks.
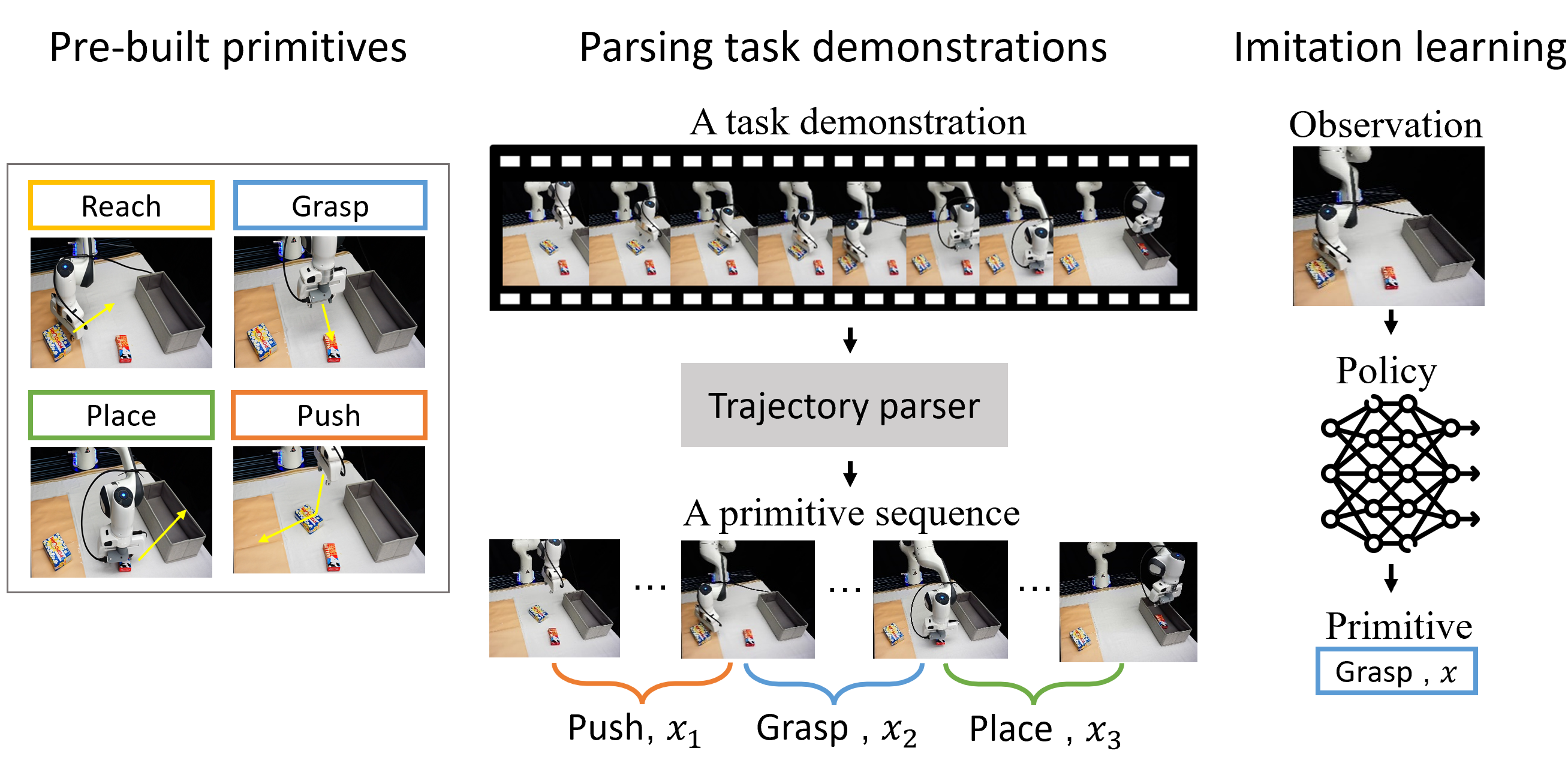
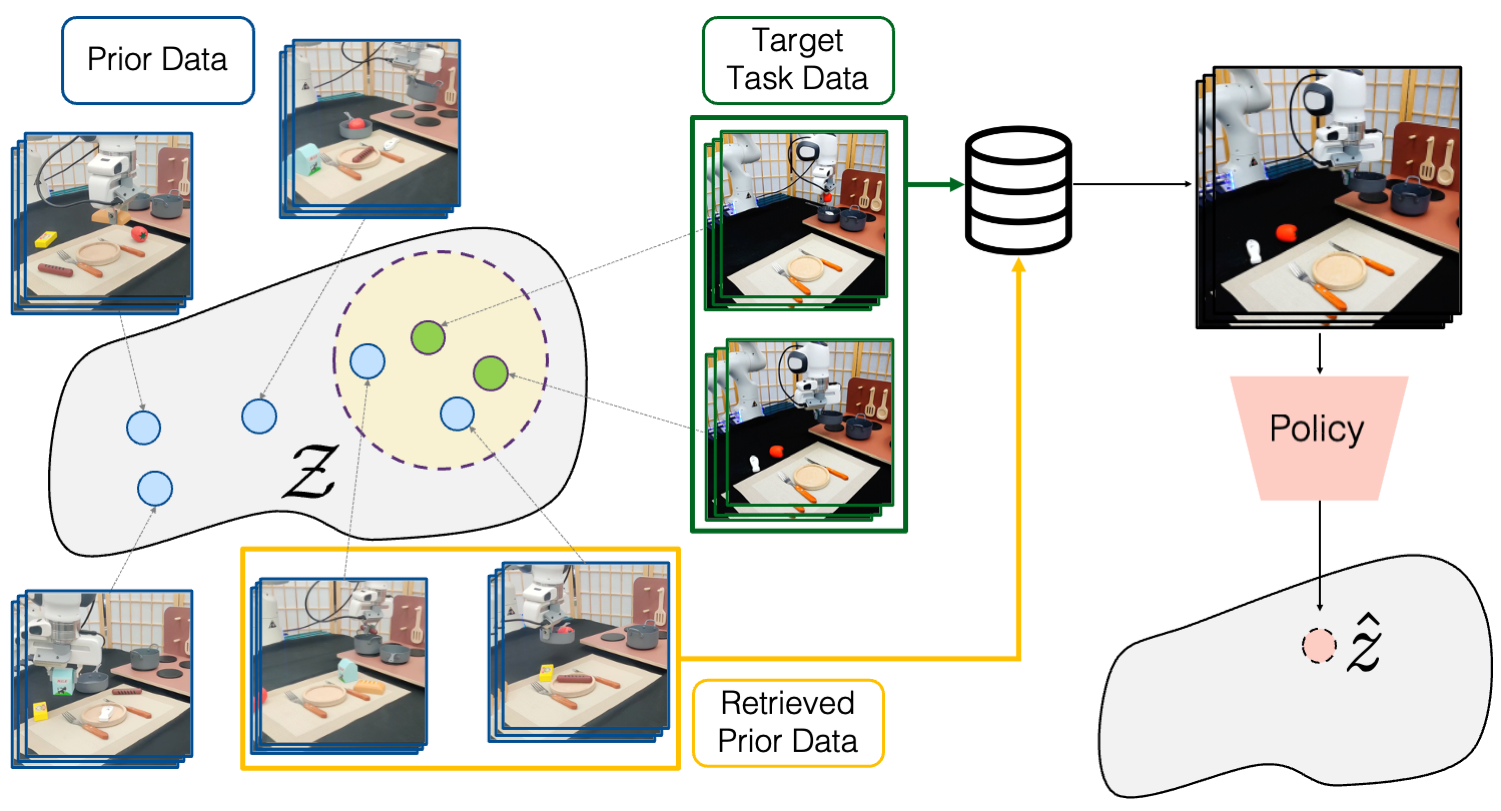
A primitive-based data-efficient imitation learning framework that scaffolds manipulation tasks with behavior primitives, breaking down long human demonstrations into concise, simple behavior primitive sequences.